Physalia [1] is a key-value store built at Amazon for the AWS Elastic Block Storage (EBS) service. The paper presenting the ideas behind it appeared at NSDI ‘20.
One of the distinct characteristics of Physalia is that by being aware of the topology of the data centre it can improve the availability of the system by reducing the probability of network partitions.
Introduction
The AWS EBS service is a block storage service used in conjunction with AWS EC2 where the volumes created by customers can be attached and detached from the EC2 instance at any point. The replication model works by using chain replication where the data flows from the client, to the primary, and then to the replica.
In case of failures, the configuration of who is the primary and who is the replica changes and it is the job of a configuration master to ensure that the changes are applied atomically. And Physalia’s responsibility is to act as this configuration master.
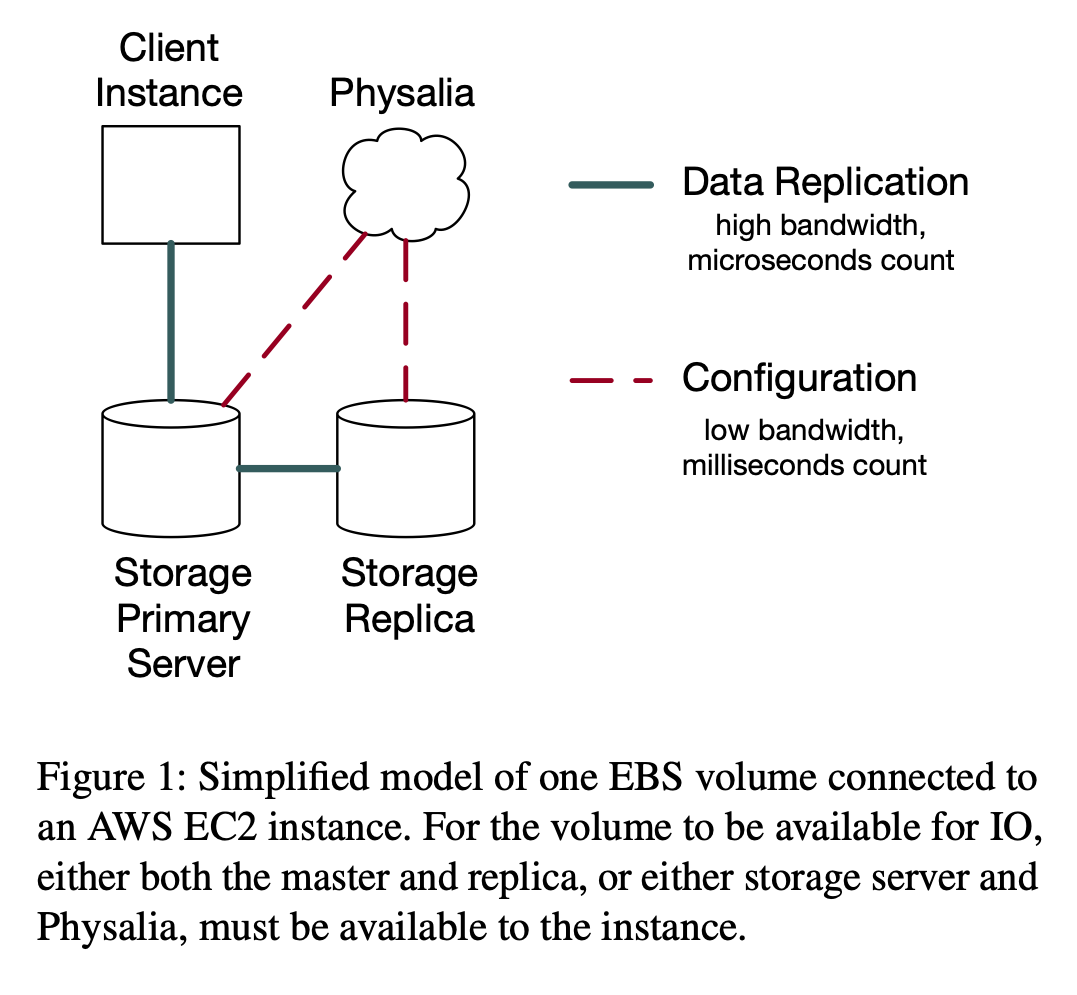
The traffic handled by the configuration master is low under normal operation, but whenever failures occur; especially if they are of a large scale; it needs to do a lot more work to handle all the reconfiguration happening due to the in-progress failures. And according to the authors:
Physalia offers both consistency and high availability, even in the presence of network partitions, as well as minimised blast radius of failures. It aims to fail gracefully and partially, and strongly avoid large-scale failures.
This is not a claim they beat the CAP theorem. In the next sections we will see what they mean by that.
Reducing the impact of incidents
The authors mention that a common practice within Amazon is to reduce the number of resources and customers that are affected when failures occur. They call it blast radius reduction. And Physalia was designed with this practice in mind. As presented before, the keys need to be available only for the clients (EC2 instances) and the replicas where the volumes are stored. By placing all the involved parties close together the probability of the system being available in that subsection are increased and less subject to incidents happening in different areas.
The design of Physalia
Physalia is organised as a colony. Each colony is comprised of several cells which live in the same environment where nodes; each running on a single server; live. Each cell manages the data of a partition key and they don’t coordinate with other cells but nodes can be members of multiple cells.
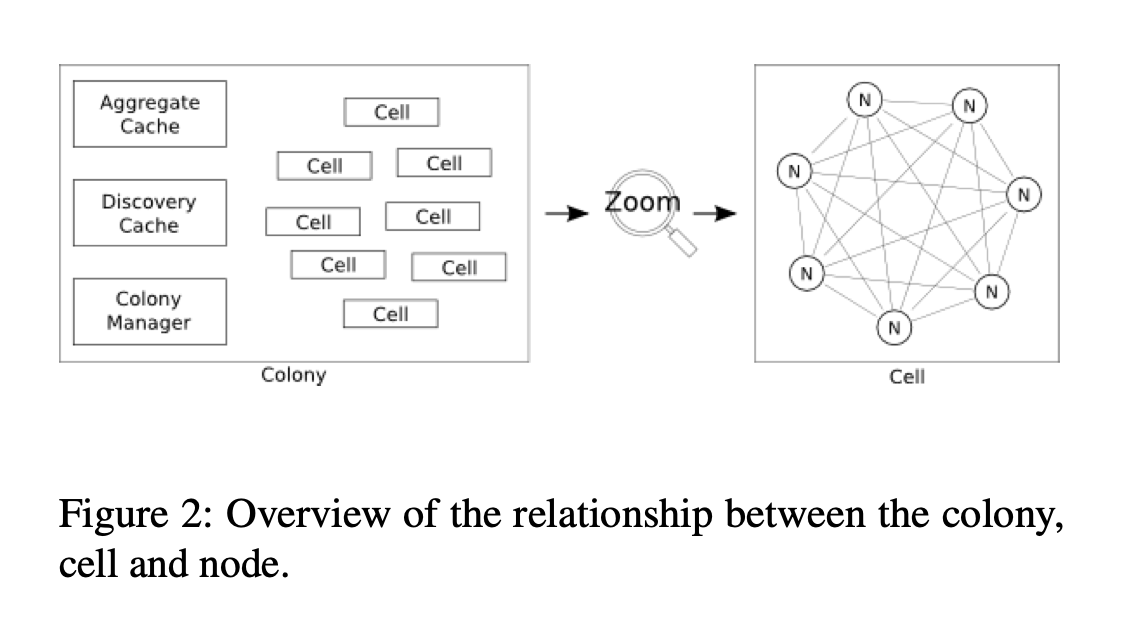
Paxos is used as the consensus algorithm for running the distributed state machine between the nodes where one of them takes the role of distinguished proposer.
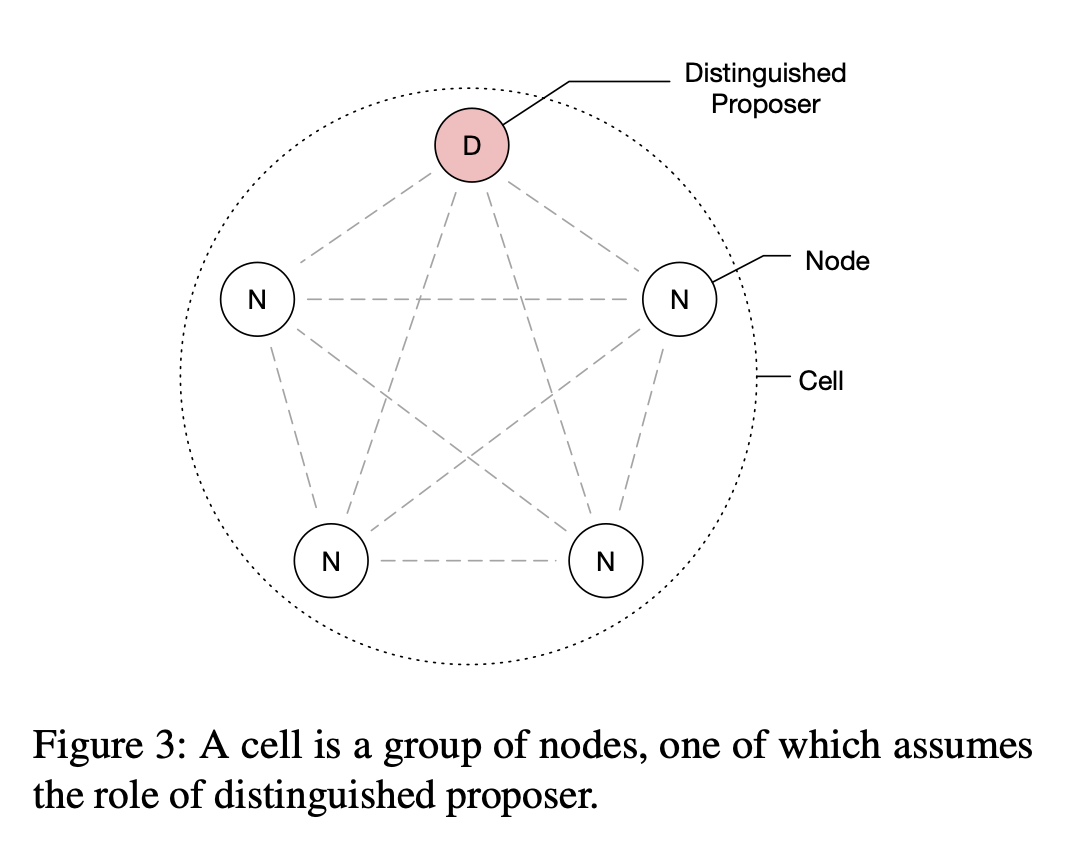
The data model used in Physalia is a partition key. The EBS volume is assigned a partition key and all of its operations happen inside the partition. Physalia offers a transactional key-value store with a consistent mode where reads and writes are linearizable and serializable. It also supports an eventually consistent mode just for reads which are mainly used for monitoring and reporting.
Reconfiguration, Teaching and Learning
An interesting aspect is when nodes join or re-join a cell and need to bring their local state to the same as the cell they are participating. The paper defines this process as teaching which is made of three modes:
- Bulk mode: the teacher; any node in the cell; transfers a bulk snapshot of its state machine to the learner;
- Log-based: the teacher sends a segment of its log to the learner;
- Whack-a-mole: in case of persistent holes in the learner’s log, it tries to propose a no-op transition in the vacant log position which is accepted if there is nothing else at that position or rejected because the position is already occupied and that value is then proposed.
Another component of the system is an eventually consistent cache, the discovery cache, which is how clients find out about the cells responsible for their partition key. The cells periodically send information to the discovery cache to inform their configuration; which partition key it is responsible for and the nodes that are part of the cell. The discovery cache has three approaches to reduce the impact in case of failures: client-side caching, forwarding pointers1, and replication of the discovery cache.
Availability concerns
In the introduction section of the paper the authors stated that Physalia offered consistency and high availability even in the presence of network partitions. The idea is to have Physalia to be at the same side of the network partition as its clients. That is why the systems is formed of cells that keep moving through the different nodes in result of changes of where their respective clients are located. EBS volumes are placed close to the EC2 instances in regards of physical and network distances. So, it is only natural that Physalia needs to be close as well. In the figure below you can have an idea of how that process is done:
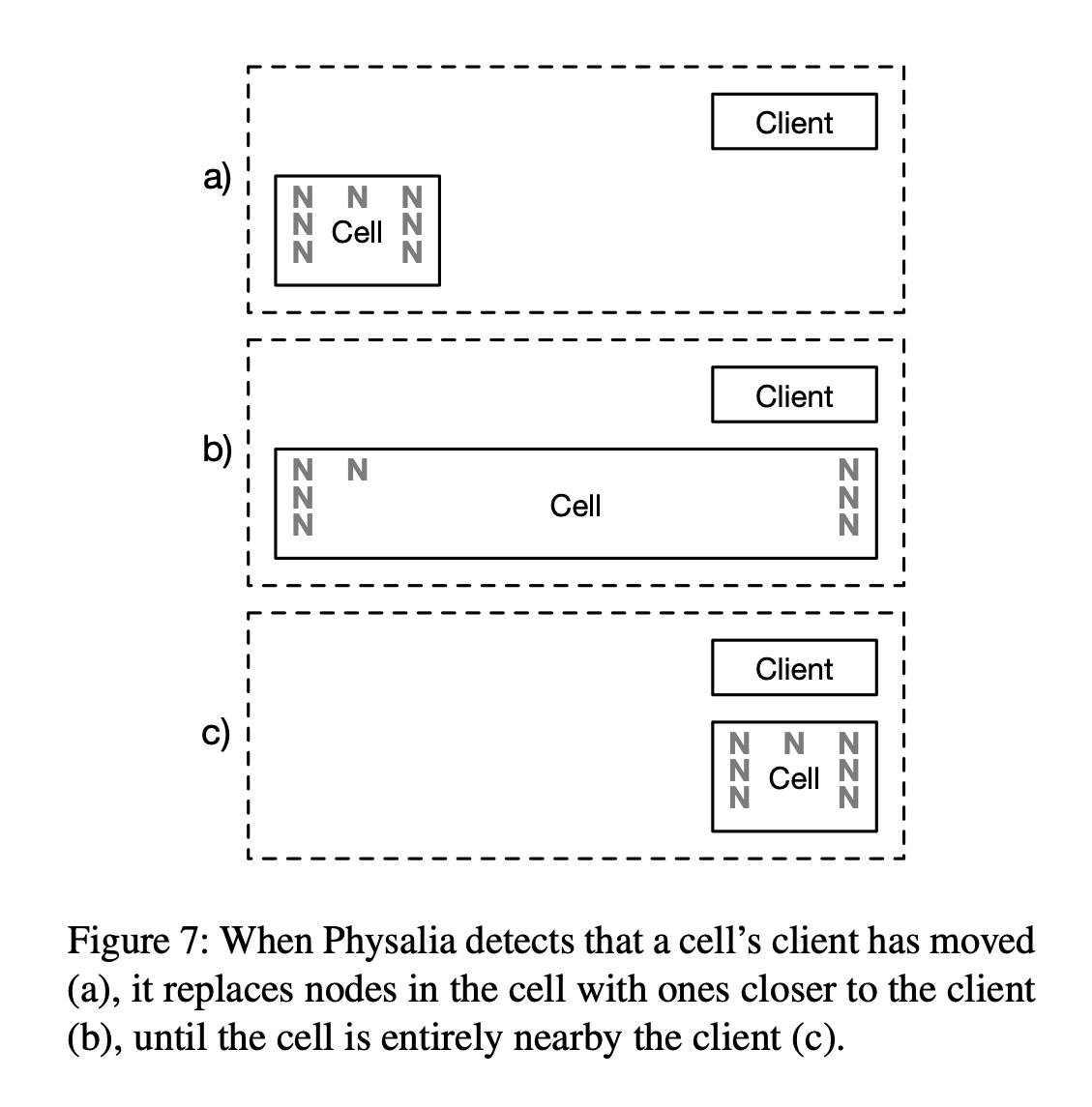
This also helps with the blast radius reduction. If a failure happens at a given section where client, nodes, and cell are located, only a subset of customers are affected.
Availability also doesn’t depend exclusively on the infrastructure details and where machines are located. The authors mention another very important aspect that influences the availability of a system:
Another significant challenge with building high-availability distributed state machines is correlated work. In a typical distributed state machine design, each node is processing the same updates and the same messages in the same order. This leads the software on the machines to be in the same state. In our experience, this is a common cause of outages in real- world systems: redundancy does not add availability if failures are highly correlated. Having all copies of the software in the same state tends to trigger the same bugs in each copy at the same time, causing multiple nodes to fail, either partially or completely, at the same time. Another issue is that the correlated loads cause memory, hard drives, and other storage on each host to fill up at the same rate. Again, this causes correlated outages when each host has the same amount of storage. Poison pill transactions may also cause outages; these are transactions that are accepted by the cell but cannot be applied to the state machine once consensus is reached.
Colouring components for isolation
In addition of having operational tasks separate by region and availability zone, they also introduced the notion of colours. Each cell has a colour and the nodes participating in a cell also have the same colour. The control plane makes sure that colours are spread through the data centre. Operations such as deployments are done colour-by-colour. Nodes of different colours don’t communicate with each other which increases the isolation between the cells and ensures that problems in certain colours don’t affect the others.
Testing
Testing practices mentioned include using TLA+ for formal verification of the protocols and to serve as documentation of such. Jepsen [2] was also used, along with what they call game days which are failure simulations in a real production or production-like environment2.
Another interesting aspect of how the system is tested is the notion of a SimWorld. By building a test harness where the network, performance, and other concepts can be abstracted they enable developers to simulate; when unit testing; different scenarios that might happen when the system is live including packet loss, corruption, server failure, etc.
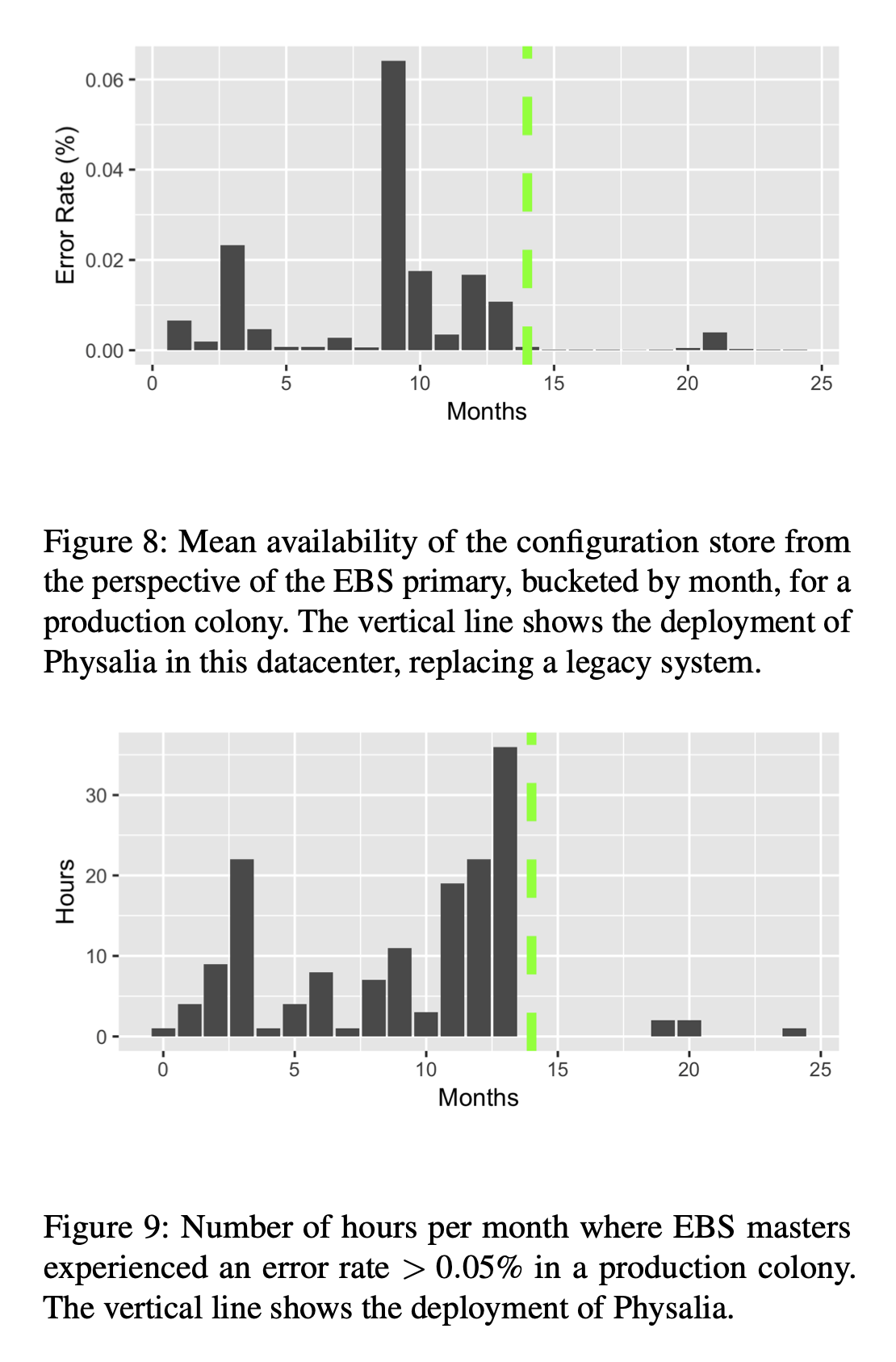
Evaluation
The production experience has been positive and the figures below will give you an idea of the impact the system had:
References
- [1] Brooker, Marc, Tao Chen, and Fan Ping. Millions of Tiny Databases. In 17th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 20), pp. 463-478. 2020.
- [2] Jepsen: http://jepsen.io